[오성고원해] 인덱스 원리와 활용 (1)
인덱스 구조
인덱스는 B*tree 구조로 되어있다.
테이블은 처음부터 끝까지 모든 레코드를 읽어야 완전한 결과집합을 얻을 수 있다 (IOT는 특정 컬럼 순으로 정렬 상태를 유지하며 값을 입력하므로 범위 스캔이 가능하다). 아무리 정렬상태가 유지되도록 해도 옵티마이저가 그것을 신뢰하여 Range Scan하지 않는다.
<--> 인덱스는 키 컬럼 순으로 정렬돼 있기 때문에 특정 위치에서 스캔을 시작해 검색 조건에 일치하지 않는 값을 만나는 순간 멈출 수 있다

- 루트, 브랜치 블록에는 하위 노드 블록을 찾아가기 위한 DBA (1800AFC) 정보를 갖는다
- 리프 블록에는 인덱스 키 컬럼과 함께 해당 테이블 레코드를 찾아가기 위한 주소정보(rowid)를 갖는다.
- LMC (LeftMost Child)는 키 값을 가지지않는다. 브랜치 첫번째 엔트리로 '키 값을 가진 첫번째 엔트리보다 작은 값'을 가진다
- LMC는 다른 엔트리와 별도 장소에 저장되어있다.

- 오라클은 인덱스 구성 컬럼이 모두 null인 레코드는 저장하지 않는다.
- 인덱스와 테이블 레코드 간에 서로 1:1 대응 관계를 갖는다. (클러스터 인덱스는 1:M관계를 갖는다)
- 브랜치에 저장된 레코드 개수는 바로 하위 레벨 블록 개수가 일치한다
-
- 리프 노드상의 인덱스 레코드와 테이블 레코드 간에는 1:1관계
- 리프 노드상의 키값과 테이블 레코드 키 값은 서로 일치
- 브랜치 노드상의 레코드 개수는 하위 레벨 블록 개수와 일치
- 브랜치 노드상의 키 값은 하위 노드가 갖는 값의 범위
인덱스 탐색
- 수직적 탐색
- 수평적 탐색을 위한 시작 지점을 찾는 과점 (루트에서 리프블록까지 아래쪽으로 진행)
- 수평적 탐색
- 범위 스캔 (리프 블록을 인덱스 레코드 간 논리적 순서에 따라 좌에서 우, 또는 우에서 좌 (DESC)으로 스캔
결합 인덱스 구조

만약 deptno = 20 and sal >= 2000 조건을 쿼리할때 (2번째부터 스캔)
ROWID 포맷
- ROWID : 데이터파일 번호, 블록번호, 로우 번호 같은 테이블 레코드의 물리적 위치정보를 포함 (그 값이 테이블에 저장하진 않음)
- 오브젝트 및 데이터파일 번호, 그리고 그 파일 내에서의 상대적인 블록 번호가 데이터 블록 헤더에 저장돼있다.
- 오라클 7까진 6바이트, 8부터는 10바이트 (파티션 기능 지원으로 오브젝트 번호까지 저장 -> 페타바이트 단위 데이터 저장)
- 6 바이트 (제한 rowid 포맷)
- 파티션되지 않은 일반 테이블에 생성한 인덱스
- 파티션된 테이블에 생성한 로컬 파티션 인덱스
- 00000DD5.0000.0001 (블록번호 + 로우번호 + 데이터파일번호)
- 블록 번호 : 해당 로우가 저장된 데이터 블록 번호, 데이터파일 내에서의 상대적 번호 (테이블 스페이스x)
- 로우 번호 : 블록내에서 각 로우에 붙여진 일련번호, 0부터 시작함
- 데이터파일 번호 : 로우가 속한 데이터파일 번호, 데이터베이스에서 유일한 값
- 10 바이트 (인덱스 블록 덤프를 통해 확인) (확장 rowid 포맷)
- 파티션 테이블에 생성한 글로벌 파티션 인덱스
- 파티션 테이블에 생성한 비파티션 인덱스
- AAAM6PAAEAAAE2cAAA (데이터 오브젝트 6 [데이터베이스 세그먼트 식별] + 데이터 파일 3 + 블록 6 + 로우 3)
- dbms_rowid 패키지를 사용하면 각 구성요소에 대한 정보를 쉽게 찾을수있다.
- 6 바이트 (제한 rowid 포맷)
인덱스 기본원리
인덱스 선두 컬럼이 조건절에 사용되지 않으면 범위 스캔을 위한 시작점을 찾을 수 없다.
-> 옵티마이저는 인덱스 전체를 스캔하거나 테이블 전체를 스캔하는 방식을 선택한다.
인덱스 컬럼을 조건절에서 가공할 경우
- 인덱스 컬럼을 조건절에서 가공 (where substr(depno, 1, 2) = '11') (단 FBI 인덱스 정의하면 가능)
- 부정형 비교 (직업 <> '학생')
- is not null (단 단일 컬럼 인덱스가 존재한다면 그 인덱스 전체를 스캔하면서 얻은 레코드는 모두 조건을 만족한다. 오라클은 단일 컬럼 인덱스에 null 값은 저장하지 않기 때문이다)
-> 정상적인 인덱스 범위 스캔 불가, 단 인덱스 사용 자체는 가능해서 Index Full Scan 가능
- is null
- 해당 조건으로는 인덱스 사용이 불가
- 만약 해당 조건절이 not null 제약이 있으면 옵티마이저는 어차피 null 값이 없는걸 알고 인덱스 스캔을 통해 공집합을 리턴
- 다른 인덱스 구성 컬럼에 is null 이외의 조건식이 하나라도 있으면 Index Range Scan 가능 (28쪽)
인덱스 컬럼의 가공 (29쪽 표 확인)
- NVL
- not null 컬럼이면 nvl 함수를 제거
- null 컬럼이면 Table Full Scan될 수 있음
- 건수가 아주 많다면 Table Full Scan
- 얼마 안된다면 함수기반 인덱스 생성 (create index 주문_x01 on 주문 (nvl(주문수량, 0) );
사례


묵시적 형변환



모든 조인 컬럼의 데이터 타입은 varchar2이다.
대상 연월에서 varchar2 컬럼에 숫자 값을 더하거나 빼는 연산을 가하면 숫자형으로 형변환이 일어난다. 묵시적 형변환 발생
숫자형, 문자형이 비교될때는 숫자형이 우선시된다.

- 묵시적 형변환은 쿼리 수행 도중 에러가 발생하거나 결과가 틀릴 수 있다는 측면이 더 중요하다.
- like로 비교할때만큼은 숫자형이 문자형으로 변환된다.
함수기반 인덱스(FBI) 활용
그닥 권장할 만한 해법은 아님
다양한 인덱스 스캔방식
Index Range Scan
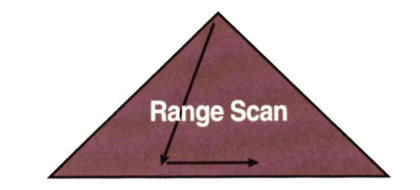
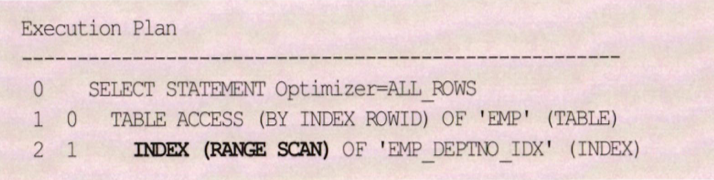
인덱스 루트 블록에서 리프 블록까지 수직적으로 탐색한 후 리프 블록을 필요한 범위만 스캔하는 방식
- 인덱스 스캔하는 범위를 얼만큼 줄일수 있는냐
- 테이블로 액세스하는 횟수를 얼마나 줄일수있느나
가 관건이며 인덱스를 구성하는 선두 컬럼이 조건절에 사용되어야한다
얘를 잘 사용하면 sort order by나 min/max 값을 빠르게 추출할 수 있다.
Index Full Scan
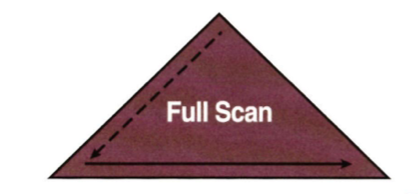

수직적 탐색없이 인덱스 리프 블록을 처음부터 끝까지 수평적으로만 탐색 (실제로는 수직적 탐색이 먼저 발생, 첫번째 리프 블록으로 찾아갈 방법이 없음)
인덱스 선두 컬럼이 조건절에 없으면 Table Full Scan 고려, 대용량 테이블이라 부담이라면 Index Full Scan 방식 고려
SELECT * FROM emp
WHERE sal > 5000
ORDER BY ename
연봉 5000을 초과하는 사원이 극히 일부라면 Index Full Scan을 통한 필터링이 큰 효과를 준다
근데 왠만해선 인덱스 구성을 조정해야한다.
Index Unique Scan
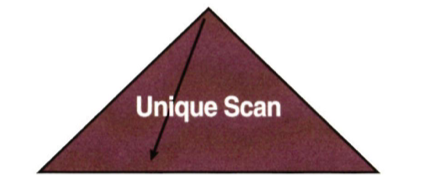

수직적 탐색만으로 데이터를 찾는 스캔 방식
인덱스 키 컬럼을 모두 '=' 조건으로 검색
Unique 인덱스라도 범위검색 (between, 부등호, like) 쓰면 Index Range Scan 된다.
Index Skip Scan
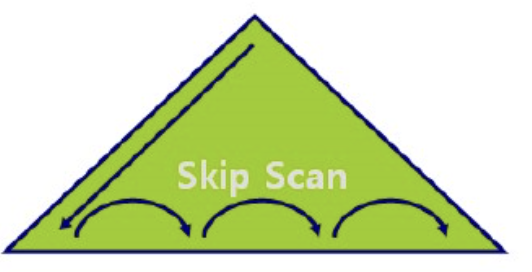

인덱스 선두 컬럼이 조건절로 사용되지 않을때 발생, 루트 또는 브랜치 블록에서 읽은 컬럼 값 정보를 이용해 조건에 부합하는 레코드를 포함할 '가능성이 있는' 리프 블록만 골라서 액세스하는 방식
조건절에 빠진 인덱스 선두 컬럼의 Distinct Value 개수가 적고 후행 컬럼의 Distinct Value 개수가 많을 때 유용
예를 들어 선두 컬럼이 성별 (남, 여) 이고 후행 컬럼이 연봉이면 선두 컬럼의 Distinct Value 는 2개이므로 Skip scan이 효율
index_ss 옵티마이저 힌트
그림은 점프하는 것처럼 보이지만 사실 다음에 방문해야할 블록을 찾는 방법은 없다.
여기서 버퍼 Pinning이 활용된다.
브랜치 블록 버퍼를 Pinning 한 채로 리프 블록을 방문했다가 다시 브랜치 블록으로 되돌아와 다음 방문할 리프 블록을 찾는 과정 반복.
브랜치 블록들 간에도 서로 연결할 수 있는 주소정보를 갖지 않기 때문에 하나의 브랜치 블록을 모두 처리하면 다시 그 상위 노드를 재 방식하는 식으로 진행된다.
인덱스 스킵 스캔이 작동하기 위한 조건
- Distinct Value 개수가 적은 선두 컬럼이 조건절에서 누락됐고 후행 컬럼의 Distinct Value 개수가 많을 때 효과적
- A + B + C 일때 B가 누락되어도 사용가능
- A + B + C 일때 A, B모두 누락되어도 사용 가능
- 선두 컬럼이 부등호, between, like 같은 범위검색 조건일때도 사용 가능
In-List Iterator 과 비교
Index Skip Scan에 의존하지 않고 더 빠르게 결과집합 얻을 수 있음
단, 해당 컬럼의 Distinct Value가 더 늘지 않음이 보장되어야하며, In-List로 제공하는 값의 종류가 적어야한다.
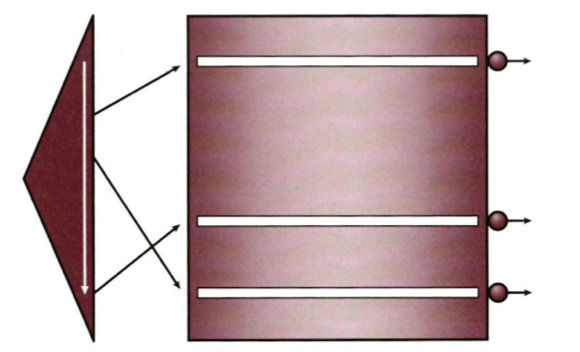
Index Fast Full Scan (index_ffs)

Index Full Scan보다 빠르다. 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔하기 때문

- 디스크로부터 대량의 인덱스 블록을 읽어야 하는 상황에서 큰 효과 발휘
- 인덱스 리프 노드가 갖는 연결 리스트 구조를 이용하지 않기 때문에 인덱스 키 순서대로 정렬하지 않음
- 쿼리에 사용되는 모든 컬럼이 인덱스 컬럼에 포함돼 있을때만 사용 가능
- 인덱스가 파티션 돼 있지 않더라도 병령 쿼리가 가능함 (Direct Path Read 가능)
- 버퍼 캐시 히트율이 낮아 디스크 I/O가 많이 발생할 때 유리함
- 컬럼 개수가 많아 테이블보다 인덱스 크기가 현저히 작은 상황에서 큰 효과, 데이터 건수가 아주 많으면 (parallel_index) 힌트 사용
Index Range Scan Descending (index_desc)


And-Equal, Index Combine, Index Join
2개 이상 인덱스를 함께 사용하는 방법
And-Equal


- 단일 컬럼의 Non-Unique 인덱스 여야 함과 동시에 인덱스 컬럼에 대한 조건절이 '='이어야 한다.
- Idex Combine이 생겨서 효용성이 없다
Index Combine

- 인덱스를 스캔하면서 조건에 만족하는 rowid 목록을 얻는다
- rowid 목록을 가지고 비트맵 인덱스 구조를 하나씩 만든다.
- 비트맵 인덱스에 대한 Bit-Wise 오퍼레이션을 수행한ㄷ.
- Bit-Wise 오퍼레이션 수행한 결과가 참인 비트 값들을 rowid 값으로 환상해 최종적으로 방문할 테이블 rowid 목록을 얻는다
- rowid를 이용해 테이블을 액세스한다.
- 데이터 분포도가 좋지 않은 두 개 이상의 인덱스를 결합해 Random 액세스량을 줄이는데 목적
- 조건절이 = 이어야할 필요가 없다 Non-Unique 인덱스일 필요도 없다.
- 조건절이 OR로 결합된 경우에도ㅗ 유용한다.
- _b_tree_bitmap_plans가 Ture일때만 작동하는데 9i부턴 디폴트가 트루임
Index Join

테이블에 속한 여러 인덱스를 이용해 테이블 액세스 없이 결과집합을 만들때 사용하는 인덱스 스캔방식
쿼리에 사용된 컬럼들이 인덱스에 모두 포함될때만 작동한다. 둘 중 한쪽만 포함되기만 하면 된다.
- 크기가 비교적 작은 쪽 인덱스에서 키 값과 rowid를 읽어 PGA 메모리에 해시 맵 생성, 해시 키로는 rowid 사용
- 다른쪽 인덱스를 스캔하면서 앞서 생성한 해시 맵에 값는 rowid 값을 갖는 레코드가 있는지 탐색
- rowid끼리 조인에 성공한 레코드만 결과집합에 포함. rowid 값이 양쪽 인덱스 집합에 모두 속한다면. 그 rowid가 가리키는 테이블은 각 인덱스 컬럼에 대한 검색 조건을 모두 만족한다는 것
테이블 Random 액세스 부하
(1) TABLE ACCESS (BY INDEX ROWID)
쿼리에서 참조되는 컬럼이 인덱스에 모두 포함되는 경우가 아니라면 인덱스 스캔 이후 '테이블 Random 액세스'가 일어난다.
(TABLE ACCESS (BY INDEX ROWID))
rowid : 오브젝트 번호 + 데이터파일 번호 + 블록 번호 -> 물리적 위치 정보로 구성되지만 테이블 레코드로 직접 연결되는 구조는 아니다.
메인 메모리 DB(MMDB)는 데이터를 모두 메모리에 로드해놓고 메모리를 통해서만 I/O를 수행하는 DB이다.
잘 튜닝된 OLTP성 오라클 데이터베이스라면 버퍼 캐시 히트율이 99%이상이고 대부분 디스크를 경유하지 않을텐데도 MMDB만큼 빠르지않다. 대량의 테이블을 인덱스를 통해 액세스를 할때는 더더욱
왜?
MMDB는 인스턴스를 기동하면 디스크에 저장된 데이터를 버퍼 캐시에 로딩하고 이어서 인덱스를 실시간으로 만듬. 이때 인덱스를 오라클처럼 디스크 상의 주소정보를 담는게 아니라 메모리상의 주소정보 (Pointer)를 담는다. 그 비용은 0에 가깝다. 인덱스를 경유해 테이블을 액세스하는 비용이 오라클과 비교할수없다.
즉, 오라클은 테이블 블록이 수시로 버퍼캐시에 밀려났다가 다시 캐싱됨. 대신 디스크 상의 블록 위치 정보 (DBA)를 해시 키 값으로 삼아 해싱 알고리즘을 통해 버퍼 블록을 찾는다. 매번 위치가 달리지더라도 캐싱되는 해시버킷만큼은 고정적
-> rowid에 의한 테이블 액세스가 생각만큼 빠르지 않은 이유
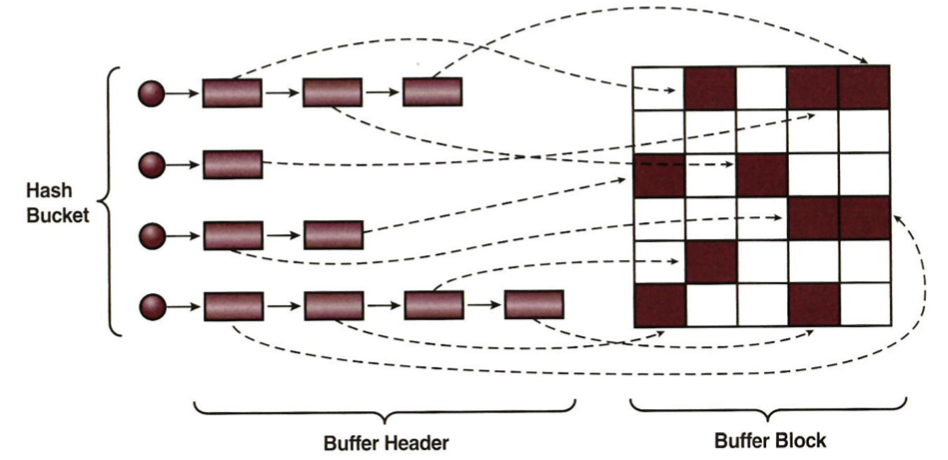
- 인덱스에서 하나의 rowid를 읽고 DBA를 해시 함수에 적용해 해시 값을 확인한다.
- 각 해시 체인은 래치에 의해 보호되므로 해시 값이 가리키는 해시 체인에 대한 래치를 얻으려고 시도한다. 하나의 cache buffers chains 래치가 여러 개 해시 체인을 동시에 관리한다
- 다른 프로세스가 래치를 잡고 있으면 래치가 풀렸는데 확인하는 작업을 일정 횟수 만큼 반복
- 그래도 실패하면 CPU를 OS에 반환하고 잠시 대기 상태로 빠진다. 이때 latch free 대기 이벤트 발생
- 정해진 시간동안 잠자다가 깨어나서 래치 확인 (안풀려있느면 다시 잠)
- 래치가 해제되었다면 래치를 획득하고 해시 체인으로 진입
- 데이터 블록이 찾아지면 래치를 해제하고 바로 읽으면 됨. 앞서 해당 블록을 액세스한 프로세스가 아직 일을 마치지 못해서 버퍼 Lock을 쥔 상태라면 다시 대기. (buffer busy waits)
- 블록 읽기를 마치고나면 버퍼 Lock을 해제해야하므로 다시 해시 체인 래치를 얻으려고 시도 (이때 경합 발생)
해시 체인을 스캔했는데 데이터 블록을 찾지못하면
- 디스크로부터 블록을 퍼 올리려면 우선 Free 버퍼를 할당받아야하므로 LRU 리스트를 스캔한다. 이때 cache buffers lru chain 래치를 얻어야하는데 래치 경합이 심할때는 latch free 이벤트가 발생
- LRU 리스트를 정해진 임계치만큼 스캔했는데도 Free 상태의 버퍼를 찾지 못하면 DBWR에게 Dirty 버퍼를 디스크에 기록해 Free 버퍼를 확보해달라는 신호를 보낸다. 그런 후 해당 작업이ㅣ 끝날때 까지 잠시 대기 상태에 빠진다. (free buffer waits)
- Free 버퍼를 할당 받은후 I/O 서브시브템에 I/O 요청을 하고 다시 대기상태에 빠진다 (db file sequential read 대기 이벤트)
- 읽은 블록을 LRU 리스트 상에서 위치를 옮겨야 하기 때문에 cache buffers lru chain 래치를 얻어야하는데 원할하지못하면 latch free 이벤트가 나타난다.
즉 인덱스 rowid는 테이블 레코드와 물리적으로 연결돼있지 않기 때문에 인덱스를 통한 테이블 액세스는 생각보다 고비용구조다. 모든 데이터가 메모리가 캐싱돼있더라도 테이블 레코드를 찾기위해 매번 DBA를 해싱하고 래치 획득 과정을 반복해야하며, 동시 액세스가 심할때는 래치와 버퍼Lock에 대한 경합까지 발생
군집성 계수 (클러스터링 팩터)

Clustering Factor은 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도를 의미한다. CF가 좋은 컬럼에 생성한 인덱스는 검색 효율이 좋다.
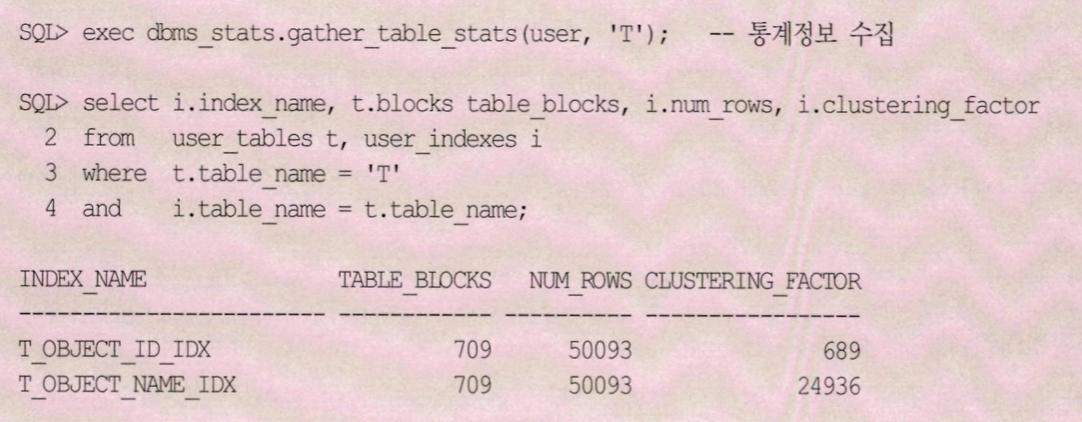
clustering_factor 수치가 테이블 블록에 가까울수록 데이터가 잘 정렬돼있음을 의미. 레코드 갯수에 가까울수록 흩어져있음을 의미.
오라클이 인덱스 통계를 수집할때 clustering_factor 계산을 위한 사용하는 로직
- counter 변수하나 선언
- 인덱스 리프 블록을 처음부터 끝까지 스캔하면서 인덱스 rowid로부터 블록 번호를 취한다.
- 현재 읽고 있는 인덱스 레코드의 블록 번호가 바로 직전에 읽은 레코드의 블록 번호와 다를때마다 counter 변수 값을 1씩 증가시킨다.
- 스캔을 완료하고서, 최종 counter 변수 값을 clustering_factor로서 인덱스 통계에 저장

- blevel : 리프 블록에 도달하기 전 읽게 될 브랜치 블록 개수
- 유효 인덱스 선택도 : 전체 인덱스 레코드 중에서 조건절을 만족하는 레코드를 찾기 위해 스캔할 것으로 예상되는 비율
- 유효 테이블 선택도 : 전체 레코드 중에서 인덱스 스캔을 완료하고서 최종적으로 테이블을 방문할 것으로 예상되는 비율
인덱스 CF가 좋다 -> 인덱스 정렬 순서와 테이블 정렬 순서가 서로 비슷하다, 인덱스를 경유해 테이블 전체 로우를 액세스할 때 읽을 것으로 예상되는 논리적인 블록 개수가 좋다.
- 물리적 I/O 횟수를 감소시키는 효과
- 오라클에서 I/O는 블록 단위로 이루어지므로 인덱스를 통해 하나의 레코드를 읽으면 같은 블록에 속한 다른 레코드들도 함께 캐싱되는 결과를 가져오고 CF가 좋으면 그 레코드들도 가까운 시점에 읽힐 가능성이 높다. 따라서 인덱스를 스캔하면서 읽는 테이블 블록들의 캐시 히트율이 높아진다
- 논리적 I/O
- CF가 좋으면 인덱스 통계에 나타나는 clustering_factor가 전체 테이블 블록 개수와 일치하고, 가장 안좋을때는 총 레코드 개수와 일치한다. (72쪽)
똑같은 개수의 레코드를 읽는데 CF에 따라 논리적인 블록 I/O 개수 차이나느 이유 : 인덱스를 통해 액세스되는 하나의 테이블 버퍼 블록을 Pinning하기 때문
버퍼 Pinning : 방금 액세스한 버퍼에 대한 Pin을 즉각 해제하지 않고 데이터베이스 Call 내에서 계속 유지하는 기능. 즉 인덱스 레코드가 같은 블록을 가리키면 래치 획득 과정을 생략하고 버퍼를 Pin한 상태에서 읽어 논리적인 블록 읽기 횟수가 증가하지 않음. (74쪽)
인덱스 손익분기점
인덱스 rowid에 의한 테이블 액세스는 생각보다 고비용이고 일정량이 넘어가면 테이블 전체를 스캔할때보다 느려짐. Index Range Scan에 대한 테이블 액세스가 Table Full Scan보다 느려지는 지점을 손익분기점이라고한다.
- 인덱스 rowid에 의한 테이블 액세스는 Random 액세스인 반면, Full Table Scan은 Sequential 방식으로 이루어짐
- 디스크 I/O시, 인덱스 rowid에 의한 테이블 액세스는 Single Block Read이지만 Full Table Scan은 Multiblock Read방식
이러한 요인으로 테이블이 인덱스보다 좋아지는 지점이 있다.
테이블을 Reorg함으로써 CF를 좋게 만들면 인덱스 손익분기점이 높아져 인덱스의 효용성이 증가하지만 이건 최후의 수단이어야함
부분범위처리 방식을 적극 활용
손익분기점 극복 방안
- IOT 테이블 : 테이블을 인덱스 구조로 생성 (즉 항상 정렬됨) 인덱스 리프 블록이 곧 데이터블록이므로 Random 액세스 불필요
- 클러스터 테이블 (Clustered Table) : 키 값이 같은 레코드는 같은 블록에 모이도록 저장, 클러스터 인덱스를 이용할 때는 테이블 Random 액세스가 키 값별로 한번 씩만 발생. 클러스터에 도달해서는 Sequential 방식으로 스캔하기 때문에 넓은 범위를 읽어도 비효율 없음
- 파티셔닝 : 대량 범위 조건으로 자주 사용되는 컬럼 기준으로 테이블을 파티셔닝하면 Full Table Scan해도 일부 파티션만 읽고 멈추도록 할 수 있다. 클러스터는 기준 키값이 같은 레코드를 블록 단위로 모아놓지만 파티셔닝은 세그먼트 단위로 모아 놓는 차이가 있다.
테이블 Random 액세스 최소화 튜닝
(1) 인덱스 컬럼 추가
80쪽 참고
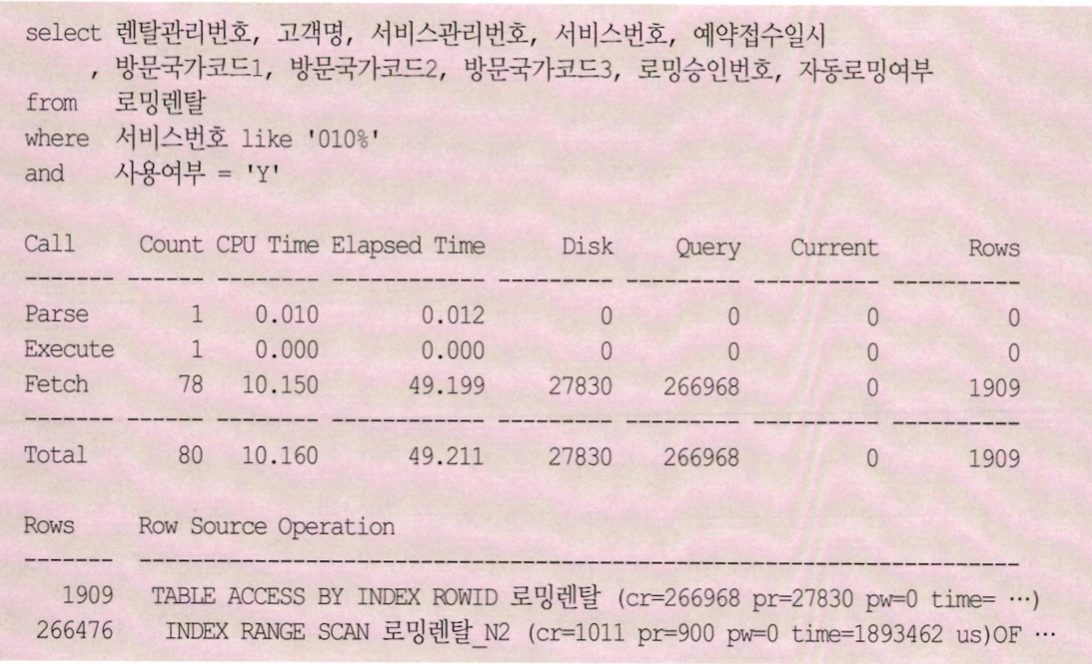
- 테이블을 액세스하는 단계에서만 265.957 (266,968 - cr, 1,011)개 I/O 발생 이는 전체 I/O의 99.6% (265.957/266.968)
- 또한 266.476(Rows) 방문하는 동안 블록 I/O가 265.957개가 발생한것은 클러스터링 팩터도 안좋음
- 가장 큰 문제는 266.476방문했지만 최종 결과집합이 1.909(테이블 액세스 단계 출력건수)개 뿐이라는 것. 테이블 방문후 사용여부에서 대부분 버려진것
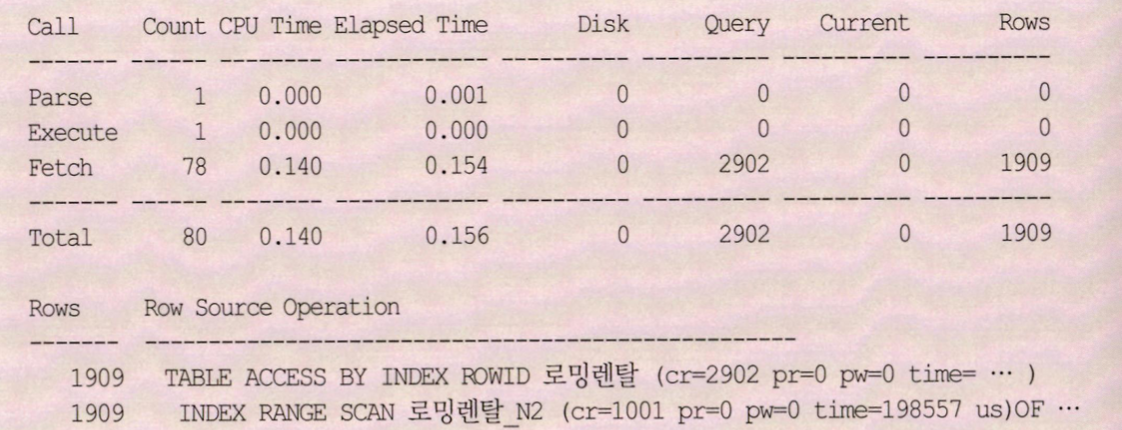
- 테이블 1909번 방문했지만 모두 결과집합에 포함되어있음
(2) PK 인덱스에 컬럼 추가

emp 기준으로 Nl 조인하고 조인에 성공한 14건 중 최종 결과집합은 3건
dept_pk 인덱스에 loc 컬럼을 추가하면 불필요한 11번의 Random 액세스를 없앨 수 있지만 PK 인덱스에는 컬럼을 추가할 수없다. 그래서 PK 컬럼 + 필터조건 컬럼 형태의 Non-Unique 인덱스를 추가하는 경우가 있다. Non-Unique 인덱스를 이용해 PK 제약을 설정한다면 인덱스 개수를 줄일 수 있다.
PK 제약에는 중복 값 확인을 위한 인덱스가 반드시 필요하다. 인덱스가 없다면 값이 입력될때마다 테이블 전체를 읽어 중복값 존재 여부를 체크해야하기 때문. 근데 Unique인덱스말고 Non-Unique 인덱스로도 가능하다. 중복 여부 체크할때 one-plue 스캔이 발생하는 비효율이있지만 무시할만하다.


PK제약을 위해 사용되는 인덱스는 PK 제약 순서와 서로 일치하지 않아도 상관없음
중복 값 유무를 체크하는 용도이므로 PK 제약 컬럼들이 선두에 있기만 하면 된다.
(3) 컬럼 추가에 따른 클러스터링 팩터 변화
인덱스에 컬럼을 추가해서 테이블 Random 액세스 부하를 줄이는 효과가 있지만 인덱스 클러스터링 팩터가 나빠지는 부작용을 초래할 수도있음 (87쪽 확인)

즉 변별력이 좋지않은 컬럼 뒤에 변별력이 좋은 다른 컬럼을 추가할때는 클러스터링 팩터 변화에 주의를 기울여야한다.
(4) 인덱스만 읽고 처리
테이블 Random 액세스가 아무리 많더라도 필터 조건에 의해 버려지는 레코드가 거의 없다면 거기에 비효율은 없다
이때는 아예 테이블 액세스가 발생하지 않도록 모든 필요한 컬럼을 인덱스에 포함시키는 방법 -> Covered 인덱스 (인덱스만 읽고 처리하는 쿼리는 Covered 쿼리)

아 그냥 90쪽 확인
인덱스 컬럼이 많아지면 DML 속도가 느려지지만 사용빈도를 감안해서 결정한것이면 이득
(5) 버퍼 Pinning 효과 활용
한번 인력된 테이블 레코드는 절대 rowid가 바뀌지 않는다. 즉 레코드 이동이 발생하지 않는다. 따라서 미리 알고있던 테이블 rowid를 이용해 레코드를 조회하는 것이 가능한다. 해당 레코드가 지워지지않으면
(6) 수동으로 클러스터링 팩터 높이기
테이블에는 데이터가 무작위로 입력되지만 그것을 가리키는 인덱스는 정해진 키순으로 정렬되기에 대개 CF가 좋지 않음.
-> 해당 인덱스를 기준으로 테이블을 재생성해서 인위적으로 CF를 좋게할수있다.
- 주의 : 인덱스가 여러 개인 상황에서 특정 인덱스를 기준으로 재정렬하면 다른 인덱스의 CF가 나빠짐 (즉 자주 사용되는 인덱스 기준으로 하기), 또한 데이터베이스의 관리 비용 증가 (테이블과 인덱스를 Rebuild하는 부담이 적고 효과가 확실할때만 사용)
95쪽확인
1. cr (Consistent Reads, 논리적 읽기)
- Undo 정보를 적용한 블록을 읽는 횟수
- 일반적으로 SQL 실행 시, 현재 SCN(System Change Number)에 맞춰 데이터 일관성을 유지해야 해.
- 변경된 블록이 있다면, Undo 정보를 적용하여 과거 시점 데이터를 조회.
- 캐시에서 블록을 읽는 경우에도 cr 값이 증가함.
- cr이 높으면 읽기 작업이 많고, Undo 블록을 자주 참조하는 상황.
📌 예시)
SELECT 쿼리를 실행할 때, 이미 버퍼 캐시에 있는 블록을 읽으면 cr 값이 증가함.
2. pr (Physical Reads, 물리적 읽기)
- 디스크에서 블록을 읽은 횟수
- 데이터가 버퍼 캐시에 없으면 디스크에서 직접 블록을 읽음.
- pr이 높으면 버퍼 캐시 히트율이 낮아서, 성능이 저하될 가능성이 높음.
📌 예시)
데이터가 캐시에 없어서, 디스크에서 읽어야 하면 pr 값이 증가.
3. pw (Physical Writes, 물리적 쓰기)
- 디스크에 블록을 기록한 횟수
- 변경된 블록을 DBWR(Database Writer)가 디스크로 플러시할 때 증가.
- INSERT, UPDATE, DELETE가 많거나, Checkpoint 발생 시 증가.
📌 예시)
트랜잭션이 많아서 데이터 변경이 잦으면 pw 값이 높아질 수 있음.