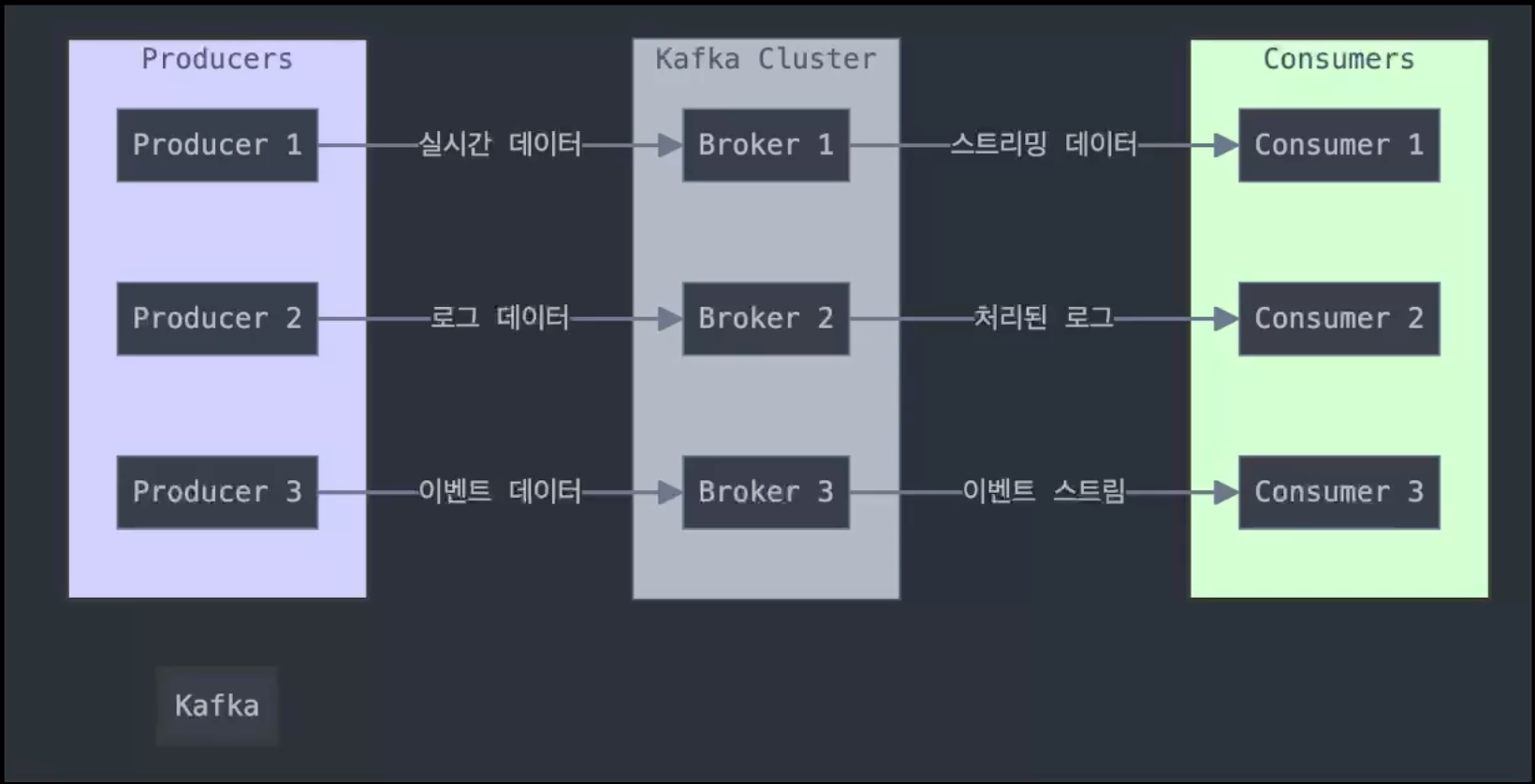
- 카프카 : 메시징 시스템 개념
- 분산 메시징 시스템
- 실시간 데이터 스트리밍
- 로그 처리
- 핵심 특징
- 확장성 : 분산 시스템 설계, 수평 확장 용이
- 내구성 : Replication 기능
- 높은 처리량 : 배치 처리와 압축 통한 성능 최적화
- 아키텍쳐 : Producer, Consumer
- Producer
- 데이터 생성 및 카프카 클러스터로 전송
- 메시지 전송 과정
- 특정 토픽의 파티션으로 데이터 전송
- 파티션 선택 전략: 라운드 로빈, 키 기반 해시
- Ack 설정
- acks = all: 높은 내구성 보장
- Consumer
- 카프카에서 데이터 읽기
- Consumer Group
- 병렬 처리 가능
- 하나의 파티션은 하나의 컨슈머에만 할당
- 데이터 중복 및 누락 방지
- offset 관리
- Producer-Consumer 흐름
- 데이터 흐름
- 프로듀서 -> 토픽 (파티션) -> 컨슈머
- 높은 처리량과 확장성
- 데이터 흐름
- 브로커
- 카프카 클러스터의 서버 노드
- 브로커 클러스터
- 여러 브로커로 구성
- 데이터 저장 및 관리
- 리더와 팔로워 구조
- 리더 : 주 데이터 처리
- 팔로워 : 데이터 복제 및 장애 복구 준비
- 토픽
- 메시지 카테고리
- 토픽의 구조
- 여러 파티션으로 구성
- 병렬 처리 가능
- 데이터 처리 전략 : 발행/구독 모델
- 브로커 - 토픽 관계
- 데이터 분산 저장
- 토픽의 파티션이 여러 브로커에 분산
- 고가용성과 성능 보장
- 데이터 분산 저장
- 파티션
- 카프카의 핵심 처리 단위
- 토픽을 구성하는 단위
- 특징
- 고유 번호 부여
- 물리적으로 다른 브로커에 분산 저장
- 병렬 처리 : 고성능 데이터 처리 가능
- 데이터 저장 구조 : 로그 파일 형식
- Replication
- 데이터 복제를 통한 내구성과 고가용성 보장
- 리더-팔로워 구조
- 리더 : 주 데이터 처리
- 팔로워 : 데이터 복제 및 백업
- Replication Factor
- 일반적으로 2~3개의 복제본 유지
- 장애 내성 vs 리소스 사용량 trade-off
- 파티션-Replication
- 내구성 보장 : 데이터 손실 방지, 고가용
- Offest
- 컨슈머의 메시지 읽기 위치 기억
- 메시지 일관성 유지
- 중복 처리 방지
- 처리 일관성 유지
- 관리 방식
- 자동 커밋 : 카프카가 자동으로 offset 저장
- 수동 커밋 : 컨슈머가 명시적으로 Offset 저장, 안정한 메시지 처리 보장
- offset과 메시지 처리 일관성
- 정확히 한번 처리 가능
- 데이터의 일관성 유지
- 중복 메시지 처리 방지
- Producer
///////
- 카프카의 역할
- 중앙 집줍형 로그 관리 시스템 구축
- 대규모 시스템에서 로그 데이터 효율적 처리
- 장애 및 성능 문제 신속 파악
- 활용 사례
- 웹 애플리케이션: 오류 로그, 성능 메트릭 수집
- 장애 탐지 및 대응 시간 단축
- 데브옵스 환경 : 인프라 상태 모니터링 및 자동화 대응
- 대규모 데이터 스트리밍 시스템
- 여러 데이터 소스에서 실시간 데이터 수집
- 스트리밍 분석 시스템으로 데이터 전송
- 적용 사례
- IOT 장치
- 실시간 데이터 파이프라인 구축
- 비즈니스 인텔리전스 : 실시간 보고서 생성 및 분석
- 사용 사례
- 중앙 로그 관리
- 여러 서버의 로그 데이터 중앙화
- 효율적인 로그 처리 및 문제 원인 추적
- ELK 스택 연동
- Elasticsearch, Logstash, Kibana와 통합
- 실시간 로그 분석 및 검색 시스템 구축
- 활용 : 실시간 로그 모니터링, 즉각적인 문제 해결
- 기술 스택 연동
- 카프카 스트림스 : 실시간 데이터 변환 및 이벤트 처리
- Apache Flink, Spark Streaming : 고급 실시간 데이터 처리
- 마이크로 서비스 아키텍쳐
- 서비스 간 비동기 통신
- 마이크로서비스 간 이벤트 기반 아키텍쳐 지원
- 확장성과 유연성 제공
- 확장 가능한 이벤트 드레이븐 시스템
- 대규모 서비스에서 고성능 비동기 통신 지원 (전자상거래, 결제, 배송)
- 서비스 간 비동기 통신
- 데이터 파이프라인
- 데이터 수집 및 변환
- 여러 소스에서 실시간 데이터 수집 및 중앙 집계
- 다양한 분석 시스템으로 데이터 전당
- Kafka Connect 활용
- 다양한 데이터 소스와 연동 (실시간 데이터 파이프라인 구축
- 데이터 수집 및 변환
- 금융 거래 처리
- 실시간 금융 거래 처리
- 대규모 트랜잭션 데이터 실시간 처리
- 빠른 거래 처리 및 정확한 데이터 분석
- Fraud Detection 시스템
- 실시간 거래 데이터 분석을 통한 분석 처리
- 실시간 금융 거래 처리
- 미디어 스트리밍 서비스
- 실시간 미지어 데이터 처리
- 스트리밍 데이터 처리 및 빠른 콘텐츠 전송
- 맞춤형 추천 및 미디어 품질 최적화
- 실시간 분석을 통한 품질 최적화
- 사용자 행동 추적 및 서비스 문제 모니터링
- 실시간 미지어 데이터 처리
- 실시간 광고 배포 시스템
- 클릭 스트림 분석
- 중앙 로그 관리
'Backend' 카테고리의 다른 글
| 카프카의 고급 기능 (0) | 2025.02.13 |
|---|---|
| Redis 개념 (0) | 2025.02.09 |
| 시스템 확장 (0) | 2025.02.08 |
| 분산 시스템 (0) | 2025.02.03 |
| 대규모 트래픽 처리 (0) | 2025.02.03 |