동시성
- 여러 작업이 동시에 진행되는 것처럼 보이도록 설계된 시스템
- 실제로는 대부분의 경우 단일 코어에서 여러 작업이 분할되어 교차로 처리
- 사용자는 각 작업이 동시에 실행되는 것처럼 느낌
- 멀티스레딩을 통해 각 작업을 독립적으로 실행 가능
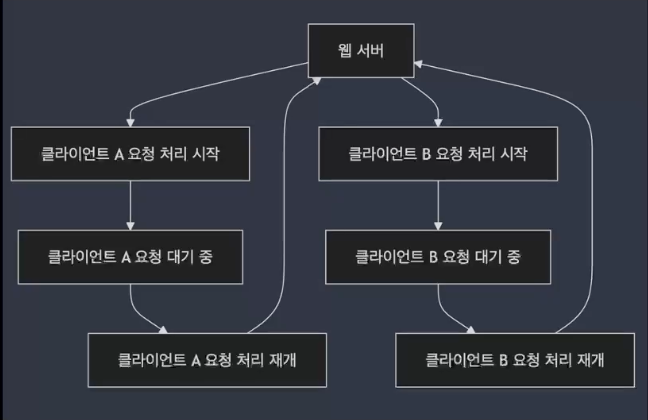
웹 서버가 여러 클라이언트의 요청을 처리할때, 각 요청에 대해 별도의 스레드를 생성하거나 작업을 교차적으로 처리하여 병렬성을 제공
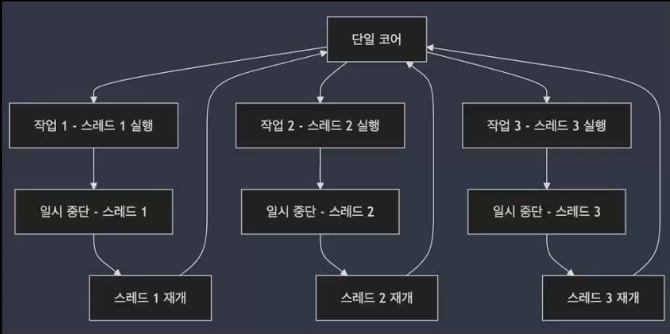
멀티스레딩 : 동시성 구현 방법
- 멀티스레딩은 하나의 프로세스 내에서 여러 스레드를 사용하여 동시성 처리를 구현
- 각 스레드는 독립적으로 실행되며, 자원을 효율적으로 사용하여 응답시간을 단축
- 병렬성 Parallelism
- 병렬성은 물리적인 개념으로, 멀티 코어에서 여러 작업이 동시에 처리되ㅡㄴ것
- 여러 코어가 동시에 각각 작업을 처리하기 때문에 실제로 작업이 동시에 수행
- 동시성
- 동시성은 논리적인 개념으로, 싱글 코어에서 여러 스레드를 번갈아가며 빠르게 실행하여 마치 동시에 여러 작업이 수행되는 것처럼 보이게 만드는 방식
- 동시성 장점
- 자원 효율성 : 시스템 자원을 최대한 활동하여 작업을 빠르게 처리
- 응답성 : 여러 작업을 동시에 처리하여 대기 시간을 줄이고, 특히 사용자 인터페이스 UI에서 중요한 역할
- 동시성 단점
- 스레드 관리 문제 : 여러 스레드를 생성하고 관리하는 것은 복잡하며, 교착상태, Race Condition 문제 발생
- 동기화 문제 : 스레드가 공유 자원을 동시에 접근할 때, 적절한 동기화 메커니즘이 없다면 데이터 손상이 발생
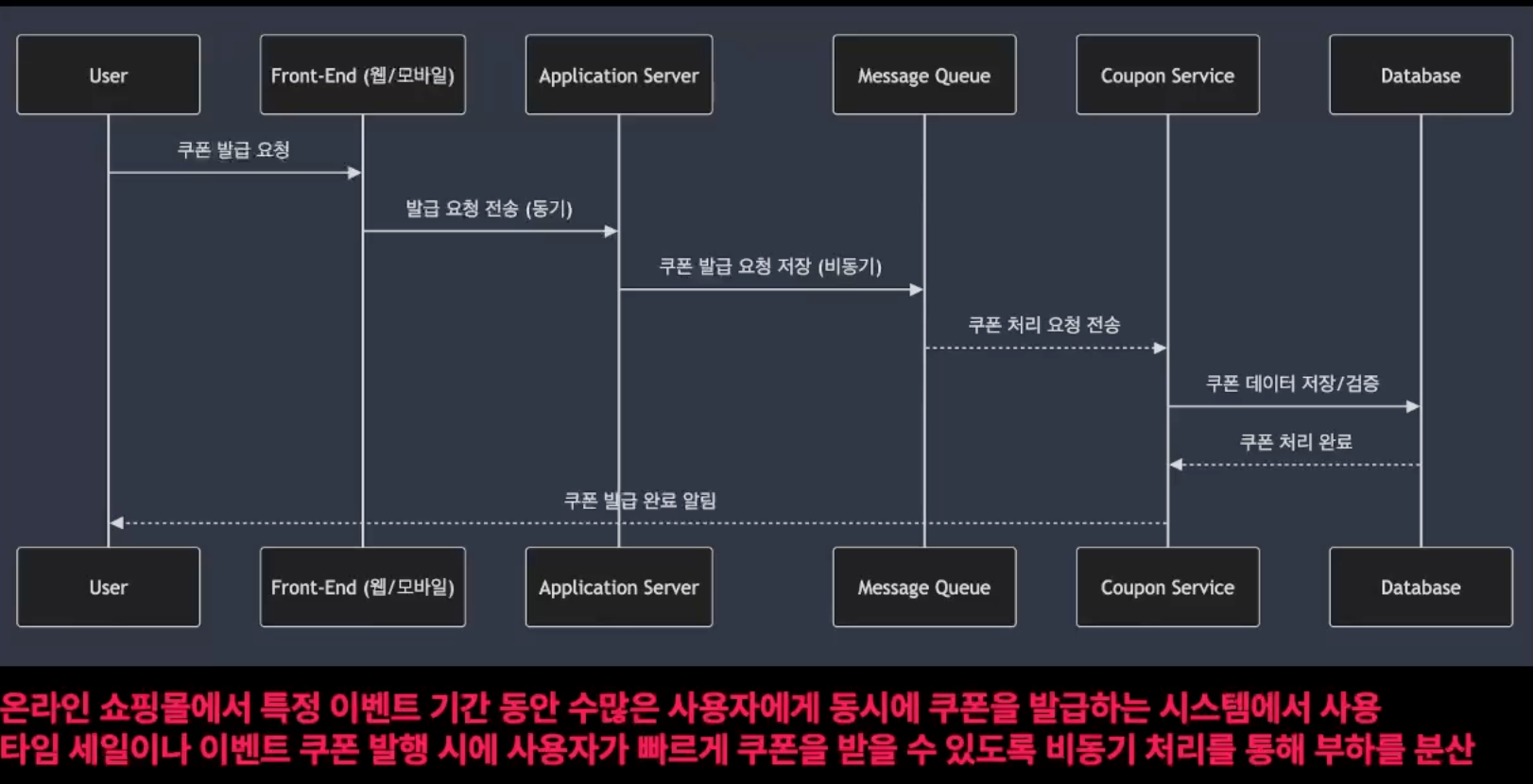
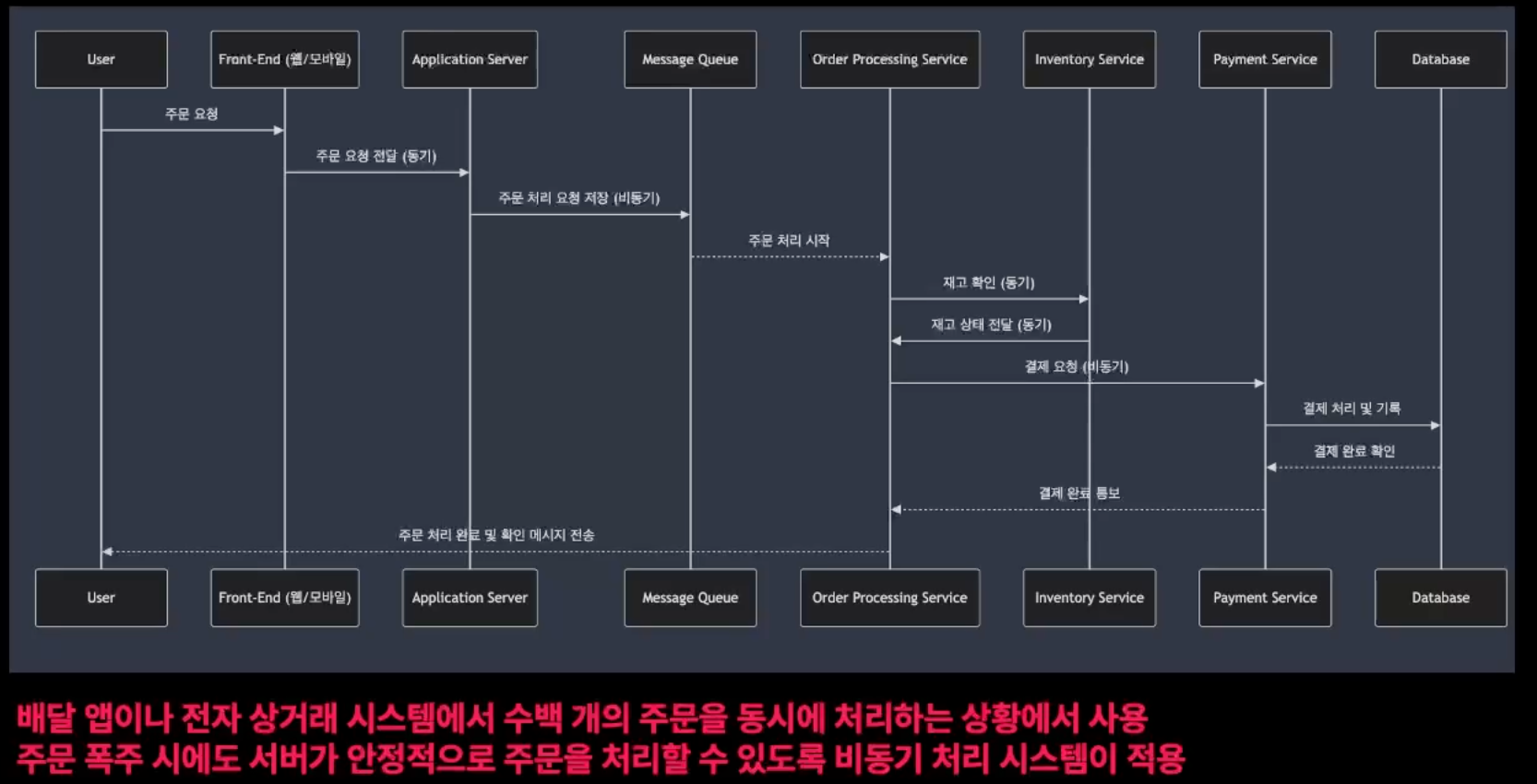
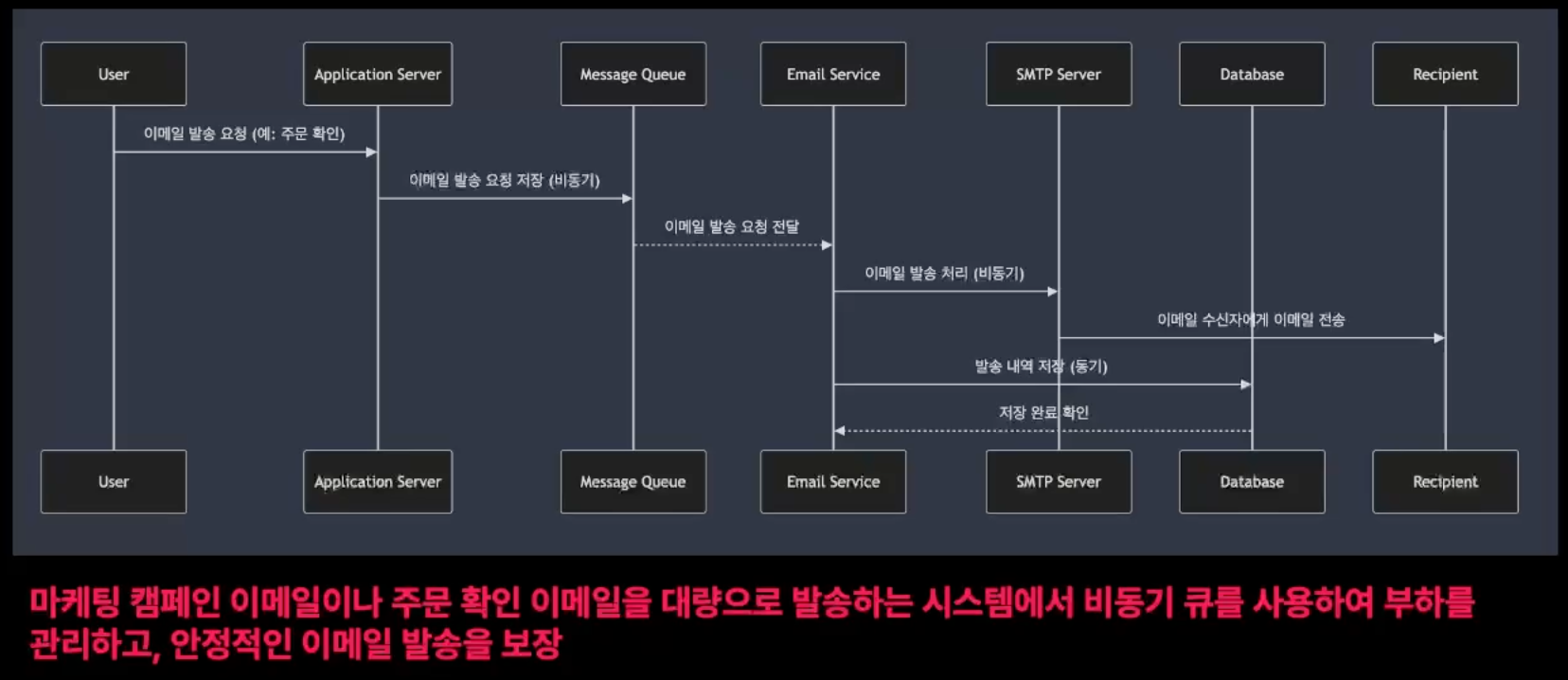
비동기 처리

비동기 처리는 특정 작업이 완료될 때까지 기다리지 않고 다른 작업을 계속 진행할 수 있는 처리 방식
이는 작업이 완료될때 까지 대기하지 않기 때문에, 시스템은 그동안 CPU자원을 다른 작업에 할당할 수 있음
작업이 완료되면 콜백이나 이벤트를 통해 결과를 알리고, 그 결과에 대한 추가 작업 수행
- 네트워크 요청 작업
- 파일 다운로드, 사용자 인터페이스
- 비동기 장점
- 병목 현상 완화 : 비동기 처리는 긴 시간이 소요되는 작업이 진행되는 동안 시스템 자원을 더 효율적으로 사용할 수 있게함
- 성능 개선 : 특히 네트워크 요청이나 파일 입출력같은 작업에서 유용
- 비동기 단점
동기와 비동기 차이
- 동기는 작업이 순차적으로 실행, 하나의 작업이 완료되기 전까지 다른 작업을 시작하지 않으며, 작업 완료를 기다린 후 다음 작업을 수행
- 비동기 처리 방식은 작업을 요청한 후 기다리지 않고 다른 작업을 처리할 수 있음. 작업이 완료되면 그 결과를 나중에 처리할 수 잇으며, 작업이 완료 될때 콜백 또는 이벤트를 통해 알림
스레드 풀
- 미리 생성된 스레드의 집합으로, 작업이 들어올 때마다 새로운 스레드를 생성하는 대신, 이미 생성된 스레드를 재사용하여 작업을 처리
- 스레드 풀을 사용하면 스레드 생성 및 소멸에 대한 오버헤드를 줄일 수 있어, 동시성 처리에서 자원을 효율적으로 관리

- 스레드 풀은 여러 작업을 동시에 처리하기 위해 미리 생성된 스레드의 집합을 유지
- 스레드 풀에 작업을 제출하면, 해당 작업이 스레드 풀의 사용 가능한 스레드에 할당
- 스레드가 작업을 마치면, 그 스레드는 다른 작업에 할당되기 전까지 대기 상태
스레드 풀 고려 요소
- 스레드 풀의 크기
- 작업의 종류 (CPU 집약적(CPU 코어에 맞게), I/O 집약적 (많은 스레드))
- 스레드 생성과 파괴 비용
- 메모리 사용량
- 동기화 문제
- 응답 시간과 처리량

- 이벤트 루프는 비동기 처리를 위한 구조로, 하나의 스레드가 여러 작업을 순차적으로 처리하는 방식
- 입출력 작업에서 매우 효율적 I/O
- 이벤트 루프는 단일 스레드 기반으로 동작하며, 비동기 작업이 완료될때마다 이벤트 큐에 있는 작업을 처리
이벤트 루프가 입출력 작업에 적합한 이유
- 논블로킹 I/O 모델
- 효율적인 자원 사용
- 반응성 유지
비동기 작업의 오류 처리 및 콜백 패턴

- 콜백 패턴
- 콜백 함수는 비동기 작업이 완료된 후 실행될 작업을 미리 등록해 두는 방식
- 단순하고 효율적이지만 콜백 지옥이라 불리는 복잡한 구조가 될 수 있음
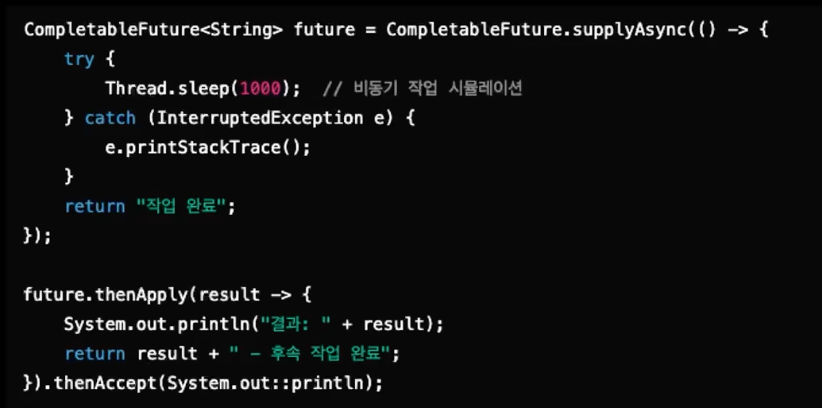
- CompletableFuture
- 비동기 작업의 결과를 비동기적으로 처리할수있는 API
- JavaScript의 Promise와 유사하며, 비동기 작업이 완료되면 그 결과를 사용해 후속 작업을 정의 가능
비동기 처리시 유의사항
- 스레드 안전성 : 스레드가 공유 자원에 접근할 때, 적절한 동기화 메커니즘 (ex. synchronized)
- 예외 처리 필요 : CompletableFutre에서 exceptionally()를 사용하여 비동기 작업에서 발생한 예외 처리