선택도와 카디널리티
- 선택도 : 전체 레코드 중에서 조건절에 의해 선택되는 레코드 비율
- 선택도 = 1 / NDV (ex. 가전, 의류, 식음료, 생활용품이 100만건 있을때 가전 선택도는 1/4 = 25%)
- 카디널리티 : 전체 레코드 중에서 조건절에 의해 선택되는 레코드 개수
- 카디널리티 = 총 로우 수 x 선택도 = 총 로우 수 / NDV (ex. 위의 예시로 카디럴리티는 25만건)
통계정보

인덱스 통계

컬럼 통계
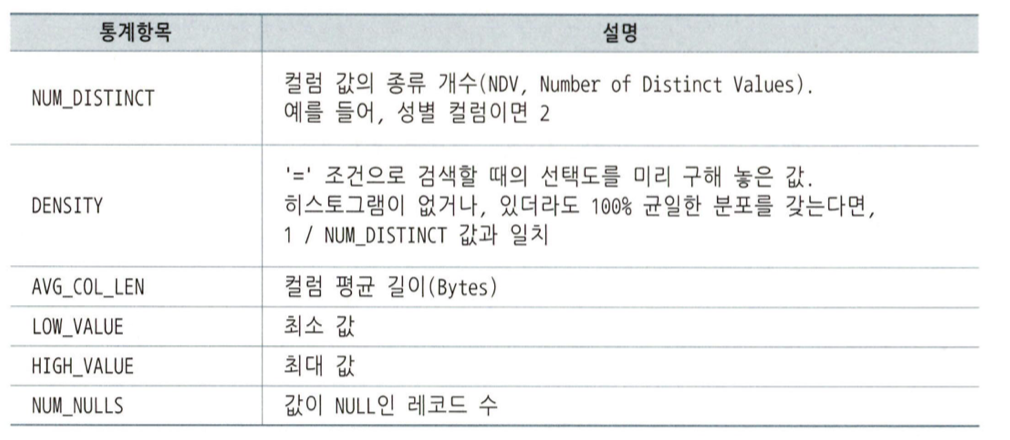
컬럼 히스토그램
데이터 분포가 균일하지 않은 컬럼에는 선택도를 잘못 구하면 데이터 액세스 비용을 잘못 산정하게 되고, 결국 최적이 아닌 실행계획으로 이어진다. 그래서 옵티마이저는 일반적인 컬럼통계 외에 히스토그램을 추가로 활용한다.

시스템 통계 (sys.aux_stats$)
- CPU 속도
- 평균적인 Single Block I/O 속도
- 평균적인 Multiblock I/O 속도
- 평균적인 Multiblock I/O 개수
- I/O 서브시스템의 최대 처리량
- 병렬 Slave의 평균적인 처리량

옵티마이저
- 비용기반 옵티마이저 : 사용자 쿼리를 위해 후보군이 될만한 실행계획들을 도출하고, 데이터 딕셔너리에 미리 수집해 둔 통계정보를 이용해 각 실행계획의 예상비용을 산정하고, 그중 가장 낮은 비용의 실행계획 하나를 선택
- 데이터량, 컬럼 값의 수, 컬럼 값 분포, 인덱스 높이, 클러스터링 팩터 사용
- 규칙기반 옵티마이저 : 통계정보 활용하지 않고 단순한 규칙에만 의존 (대량 데이터를 처리하는 데 부적합)
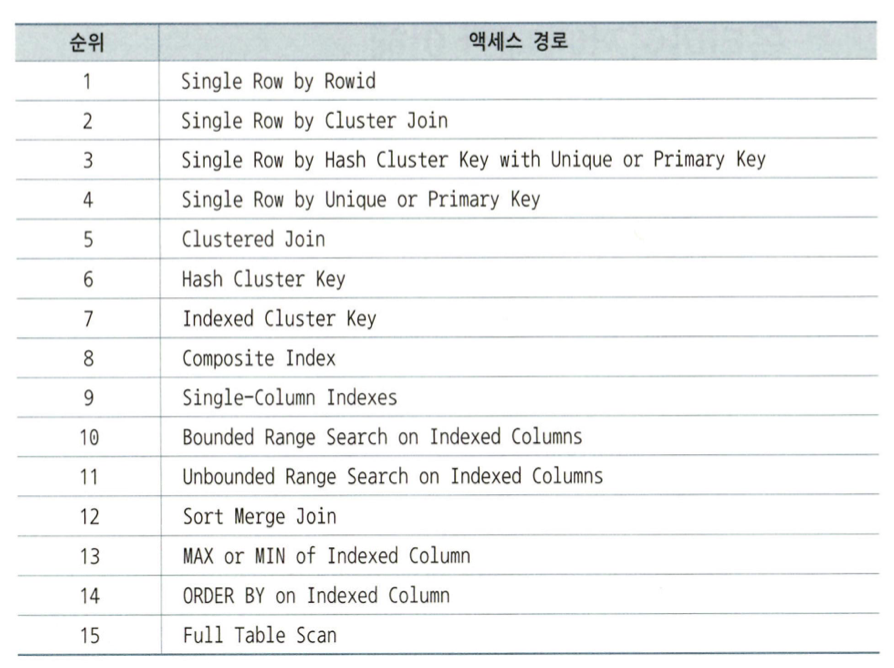

옵티마이저에 영향을 미치는 요소
- SQL과 연산자 형태
- 인덱스, IOT, 클러스터, 파티션, MV 등 옵티마이저 팩터
- 제약 설정
- 통계정보
- 옵티마이저 힌트
- 옵티마이저 관련 파라미터
'SQLP > SQLP' 카테고리의 다른 글
| 6-4. Lock과 트랜잭션 동시성 제어 (2) (0) | 2025.02.23 |
|---|---|
| 6-4. Lock과 트랜잭션 동시성 제어 (0) | 2025.02.23 |
| 6.3 파티션 을 활용한 DML 튜닝 (2) (0) | 2025.02.22 |
| 6.3 파티션을 활용한 DML 튜닝 (1) (0) | 2025.02.22 |
| 6-1, DML 기본 튜닝 (2) (0) | 2025.02.21 |