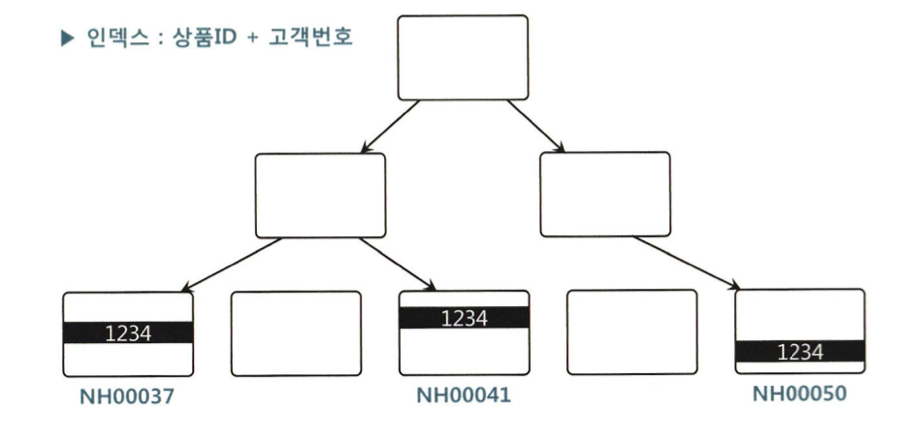
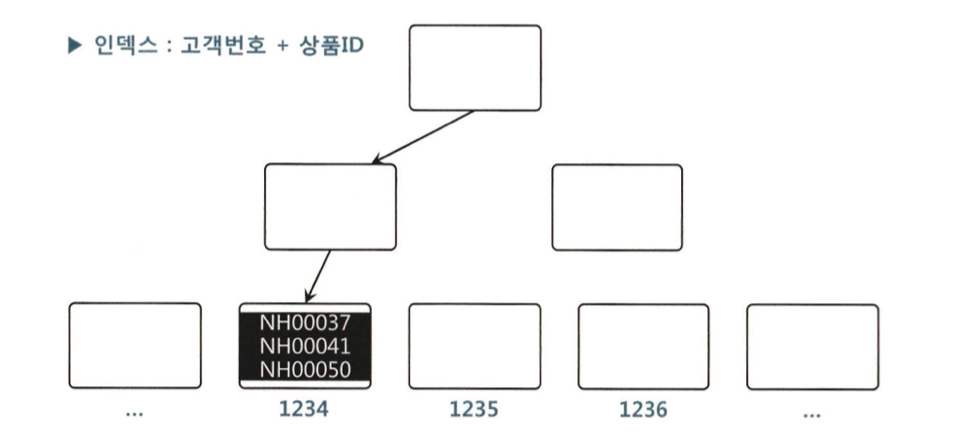
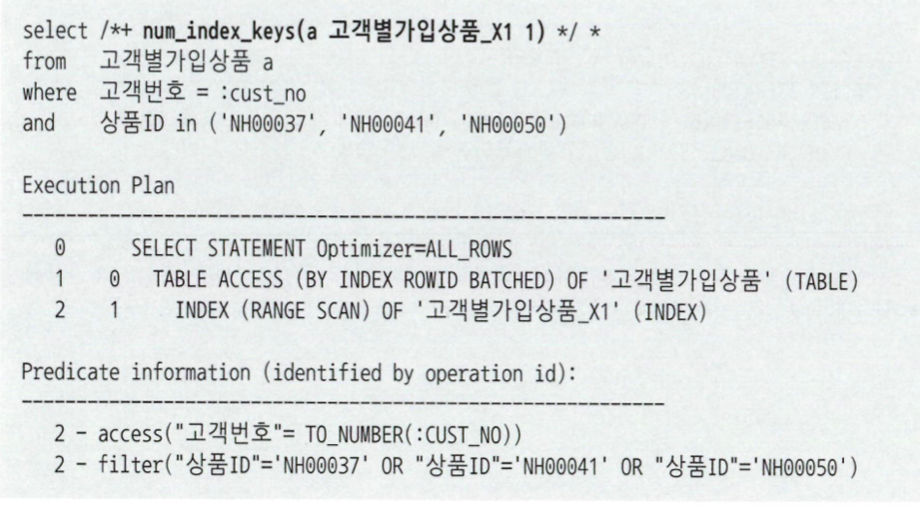
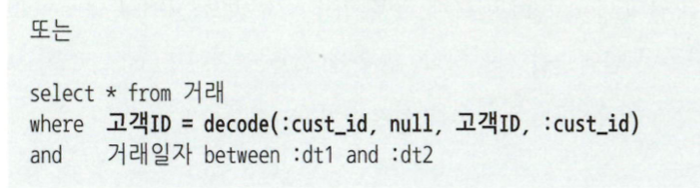
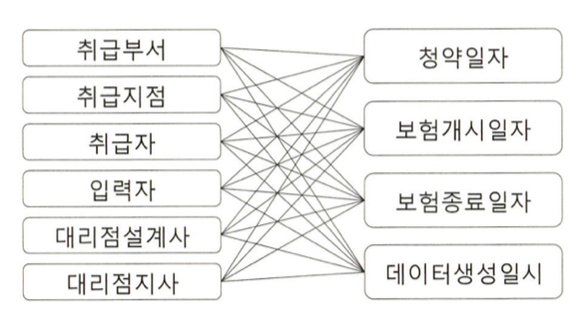
NL조인 -> 랜덤 I/O땜시 대량 데이터 처리가 안좋고 버퍼캐시 히트율에 따라 성능이 일정하지않음
소트 머지 조인 -> 항상 양쪽 테이블을 정렬해야함
그럼 해시 조인은 신인가?
기본 매커니즘
1. Build 단계 : 작은 쪽 테이블 (Build Input)을 읽어 해시 테이블(해시 맵)을 생성한다.
2. Probe 단계 : 큰 쪽 테이블 (Probe Input)을 읽어 해시 테이블을 탐색하면서 조인한다.
옵티마이저는 use_hash

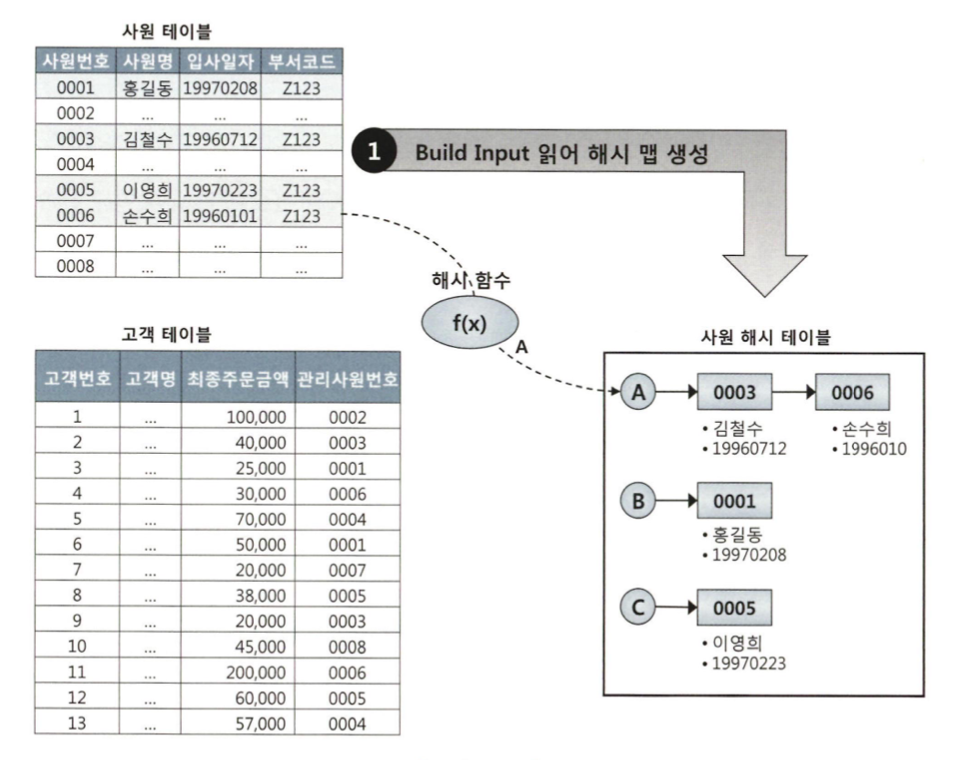
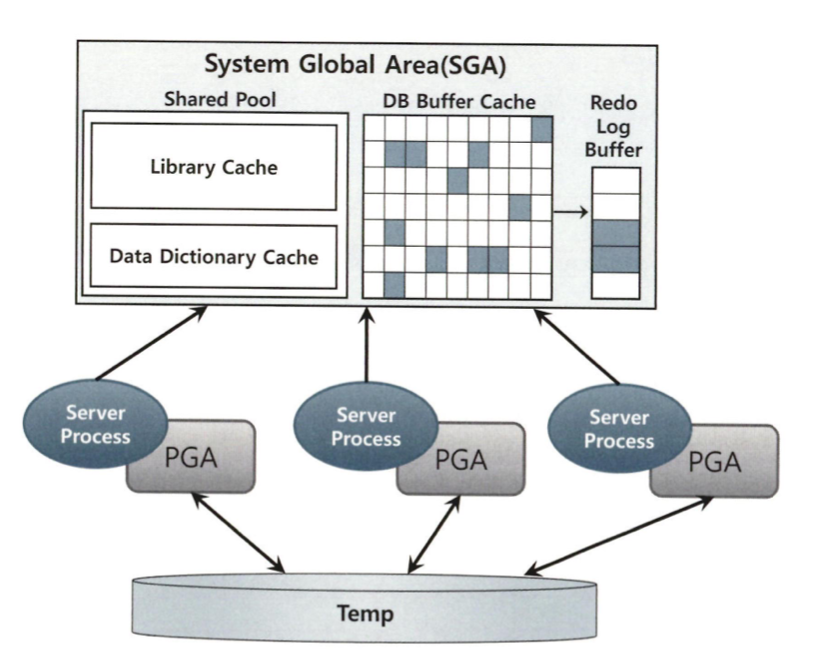
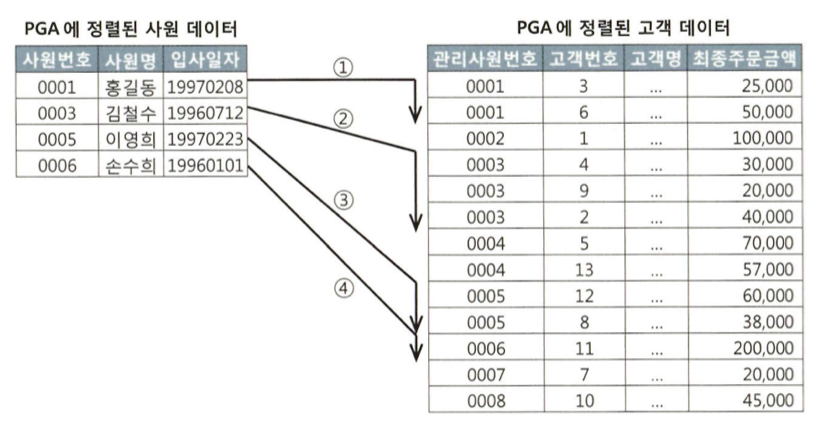
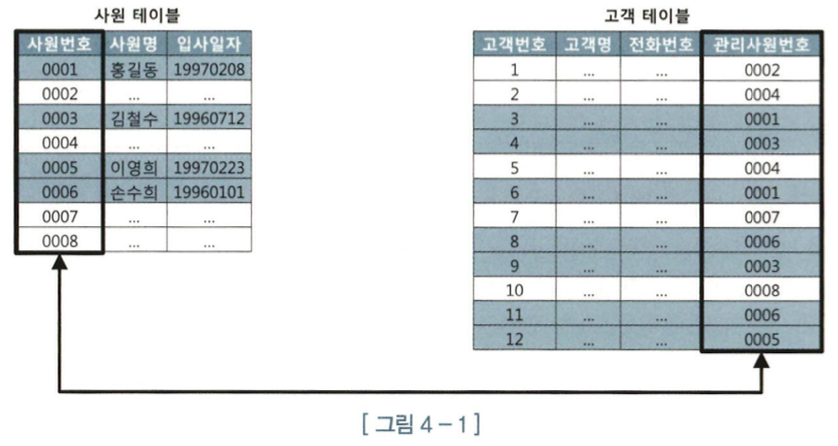
1. Build 단계 : 조건절에 해당하는 사원 데이터를 읽어 해시 테이블을 생성한다. 이때 조인 컬럼인 사원번호를 해시 테이블 키 값으로 사용한다. 사원번호를 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고, 그 해시 체인에 데이터를 연결한다. 해시 테이블은 PGA 영역(꽉 찼으면 Temp)에 할당된 Hash Area에 저장

2. Probe 단계 : 조건에 해당 (최종주문금액 >= 20000) 하는 고객 데이터를 하나씩 읽어 생성한 해시 테이블을 탐색한다. 즉 관지사원번호를 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고, 그 해시 체인을 스캔해서 값이 같은 사원번호를 찾는다. 찾으면 혁명 못찾으면 반역
해시 조인이 빠른 이유
해시 테이블을 PGA 영역에 할당하기 때문에 소트 머지 조인과 같이 래치 획득 과정이 생략됨. 해시 조인도 Build Input과 Probe Input 각 테이블을 읽을 때는 DB 버퍼캐시를 경유하고 인덱스를 이용함. -> 버퍼캐시 탐색비용, 랜덤 액세스 부하 발생
근데 소트 머지보다 해시가 더 빠름
-> 소트 머지는 '양쪽' 집합을 모두 정렬해서 PGA에 담음. 두 집합 중 하나가 대형이면 Temp 테이블 스페이스 즉 디스크에 쓰는 작업을 반드시 수반한다.
-> 해시 조인은 '한쪽'을 읽는데 둘 중 작은 집합을 해시 맵 Build Input으로 선택하므로 왠만해서 Temp를 쓸일이 없다.
---> NL 조인처럼 조인 과정에서 랜덤 액세스 부하가 없고, 양쪽을 미리 정렬하는 부하도 없다. 훌륭하다.
대용량 Build Input 처리
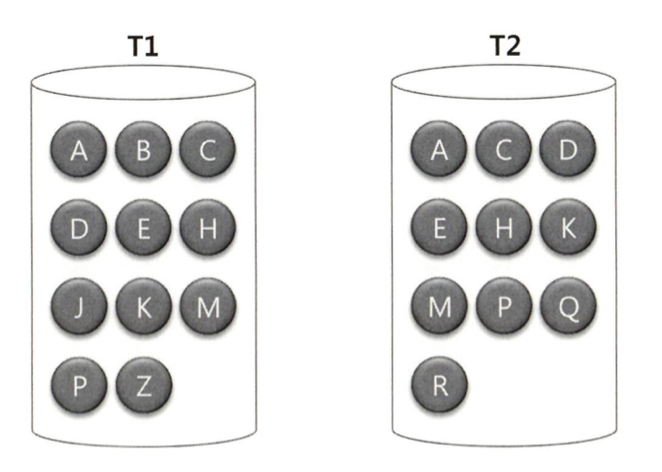
두 테이블은 대용량이라 인메모리 해시 조인이 안된다.
-> 그러때 분할 정복 알고리즘을 사용한다.
1. 파티션 단계

조인하는 양쪽 집합 (조인 이외 조건절을 만족하는 레코드)의 조인 컬럼에 해시 함수를 적용하고, 반환된 해시 값에 따라 동적으로 파티셔닝한다. 즉 독립적으로 처리할 수 있는 여러 개의 작은 서브 집합으로 분할함으로써 파티션 짝을 생성한다.
양쪽 집합을 읽어 디스크 Temp 공간에 저장해야하므로 인메모리 해시 조인보다 성능 떨어짐
2. 조인 단계
파티션 단계를 완료하면 각 파티션 짝에 대해 하나씩 조인을 수행한다 -> 이때 해시 조인과정(빌드 & 프루브)는 독립적으로 결정된다.
해시 테이블을 생성하고 나면 반대쪽 파티션 로우를 하나씩 읽으면서 해시 테이블을 탐색한다. 모든 파티션 짝에 대한 처리를 마칠때 까지 이 과정을 반복
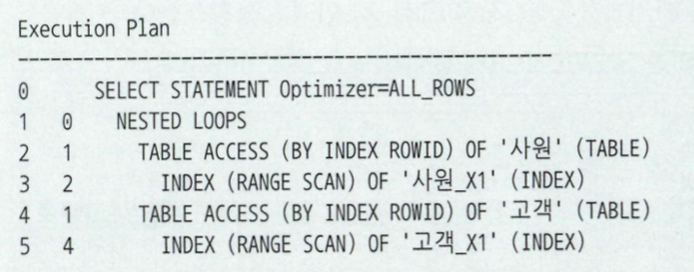
실행계획

위쪽 사원 데이터로 해시 테이블 생성한후, 아래쪽 고객 테이블에서 읽은 조인 키 값으로 해시 테이블을 탐색하면서 조인한다.
(사진은 Index를 이용하여 Build Input, Probe Input을 읽었지만 Table Full Scan도 간능)
swap_join_inputs로 Build Input을 명시할 수 있다.
3개 이상 테이블이면?

경로 1 : A와 B를 조인하고 B와 C 조인
경로 2: A와 B를 조인, A와 C를 조인 (근데 이건 복잡하니까 걍 경로 1로 고정하자)
leading 힌트를 통해 순서를 조정한다
이때 첫번째 파라미터로 지정한 테이블이 무조건 Build Input으로 선택됨






조인 메소드 선택 기준
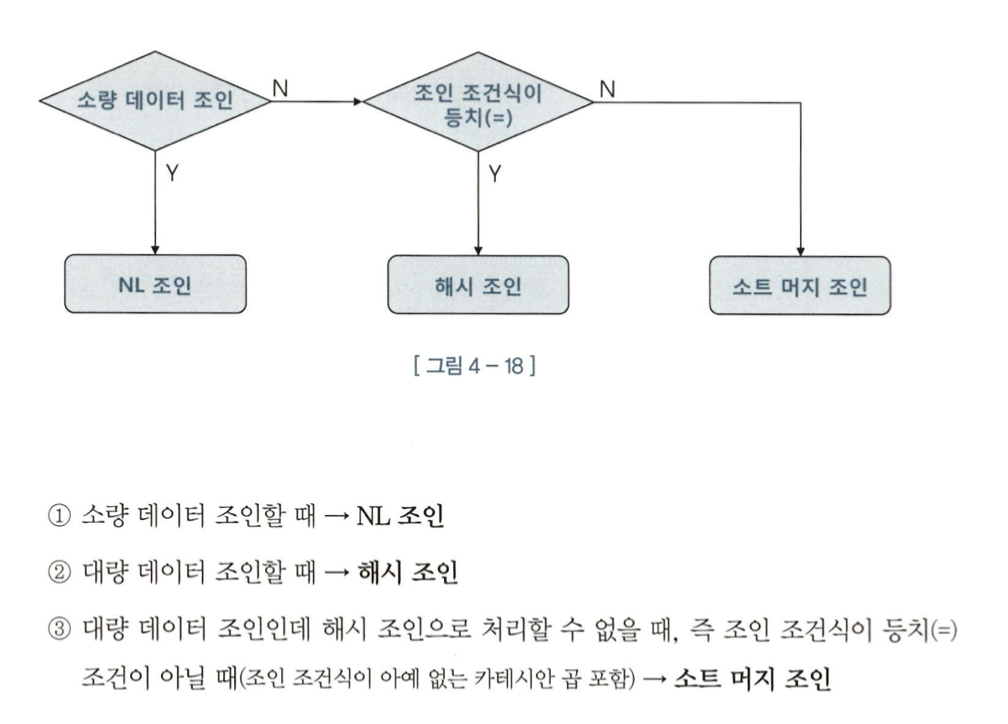
대량의 데이터는 많고 적음이 아니라 NL 조인 기준으로 최적화했음에도 랜덤 액세스가 많아 성능이 적을때이다.
수행 빈도가 매우 높은 쿼리의 기준
- NL조인과 해시 조인 성능이 같으면 NL 조인
- 해시 조인이 약간 더 빨라도 NL 조인
- NL 보다 해시 조인이 매우 빠르면 해시
어쨋뜬 NL조인이 항상 가장 먼저 고려되어야한다.
NL 조인에 사용하는 인덱스는 영구적으로 유지하면서 다양한 쿼리를 위해 공유 및 재사용하는 자료구조
<> 반면에 해시 테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 곧바로 소멸
--> 같은 쿼리를 100개 수행하면 해시 테이블도 100개 만들어짐
----> 수행시간 짧으면서 수행빈도가 매우 높은것을 해시 조인으로 처리하면 CPU와 메모리 사용률이 크게 증가한다. 해시 맵을 만드는 과정에서 래치 경합도 발생한다.
즉 해시조인은
- 수행 빈도가 낮고
- 쿼리 수행 시간이 오래 걸리는
- 대량 데이터 조인 할때
--> 배치 프로그램, DW, OLAP성 쿼리의 특징
배치 프로그램
대량의 데이터를 일괄적으로 처리하는 프로그램입니다 보통 정해진 시간(예: 매일 새벽)에 실행되어 대량의 데이터를 처리합니다 실시간 처리가 필요없는 데이터 정제, 통계 집계, 리포트 생성 등에 사용됩니다 장애 발생시 재처리가 가능하도록 멱등성을 보장해야 합니다 예: 일일 매출 집계, 월말 정산, 고객 세그먼트 분석 등
DW (Data Warehouse)
기업의 의사결정을 지원하기 위한 통합 데이터 저장소입니다 운영 데이터베이스(OLTP)의 데이터를 추출/변환하여 적재합니다 데이터는 주제별로 통합되고 시계열로 저장됩니다 일반적으로 Star Schema나 Snowflake Schema 모델을 사용합니다 데이터 중복을 허용하여 조회 성능을 최적화합니다
OLAP (Online Analytical Processing)
다차원 데이터 분석을 위한 기술입니다 주로 DW의 데이터를 사용하여 다양한 관점의 분석을 수행합니다 Drill-down, Roll-up, Slice, Dice 등의 분석 연산을 제공합니다 복잡한 집계 쿼리가 많고 대량의 데이터를 처리합니다 예: "지역별, 상품별, 기간별 매출 분석" 같은 다차원 분석
'SQLP > SQLP' 카테고리의 다른 글
| 5-1. 소트 연산 이해 (0) | 2025.02.01 |
|---|---|
| 4-4. 서브쿼리 조인튜닝 (0) | 2025.01.31 |
| 4-2. 소트 머지 조인 (0) | 2025.01.28 |
| 4-1. NL 조인 (0) | 2025.01.27 |
| 3.3 인덱스 스캔 효율화 2 (0) | 2025.01.26 |