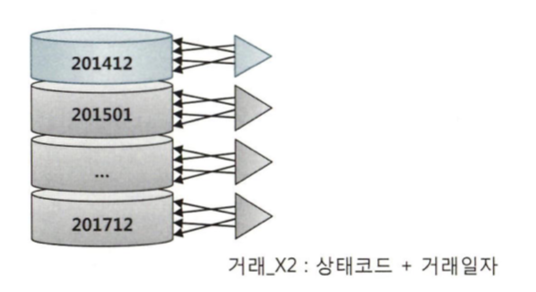
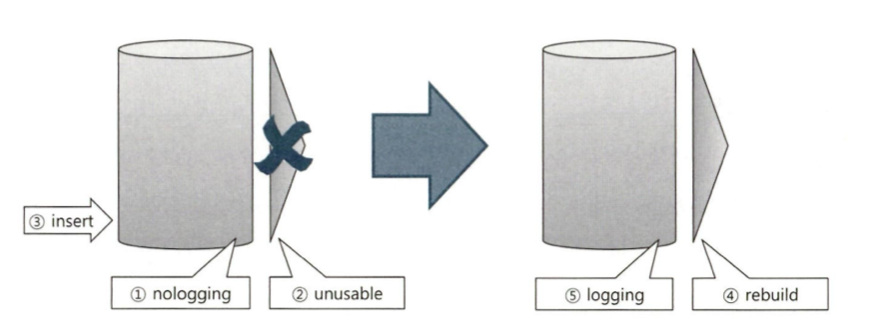
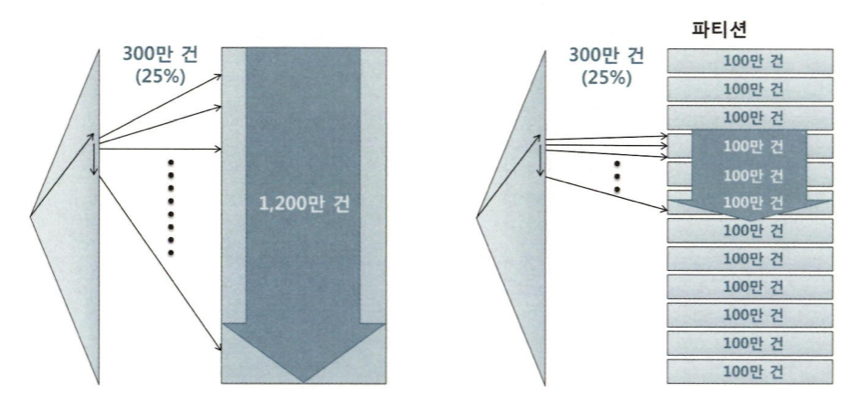
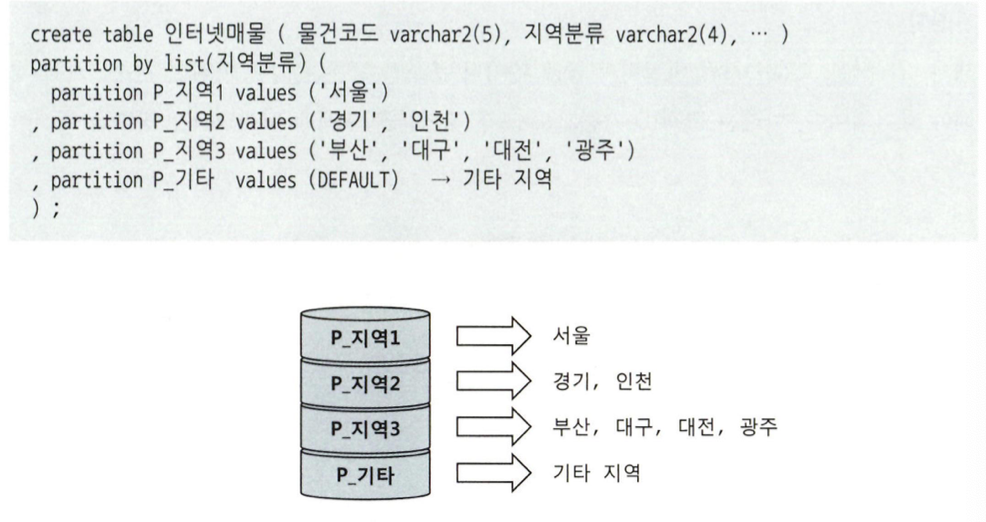
Lock은 데이터베이스 특징을 결정짓는 가장 핵심적인 메커니즘
오라클 Lock
공유 리소스와 사용자 데이터를 보호할 목적으로 다양한 종류의 Lock을 사용한다.
- DML Lock : 다중 트랜잭션이 동시에 액세스하는 사용자 데이터의 무결성 보호
- 테이블 Lock
- 로우 Lock
- DDL Lock
- 래치 : SGA에 공유된 각종 자료구조를 보호하기 위해 사용됨
- 버퍼 Lock : 버퍼 블록에 대한 액세스를 직렬화하기 위해 사용
- 라이브러리 캐시 Lock/Pin : 캐시에 공유된 SQL 커서와 PL/SQL 프로그램을 보호하기 위해 사용
DML Lock
- 로우 Lock : 두 개의 동시 트랜잭션이 같은 로우를 변경하는 것을 방지 -> 하나의 로우를 변경하려면 로우 Lock 먼저 설정
- DML 로우 Lock 에는 베타적 모드를 사용하므로 UPDATE 또는 DELETE를 진행중인 로우를 다른 트랜잭션이 UPDATE 하거나 DELETE할 수 없다.
- INSERT에 대한 로우 Lock 경합은 Unique 인덱스가 있을 때만 발생한다. 즉 Unique 인덱스가 있는 상황에서 두 트랜잭션이 같은 값을 입력하라고 할때 블로킹이 발생한다. 블로킹이 발생하면 후행 트랜잭션은 기다렸다가 선행 트랜잭션이 커밋하면 INSERT에 실패하고 롤백하면 성공한다. 두 트랜잭션이 서로 다른 값을 입려갛거나 Unique 인덱스가 아예 없으면 INSERT에 대한 로우 Lock 경합은 발생하지 않는다.
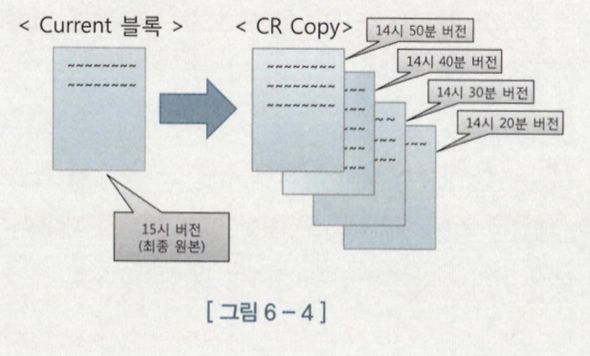
- MVCC 모델을 사용하는 오라클은 SELETE 문에 로우 Lock을 사용하지 않는다. 오라클은 다른 트랜잭션이 변경한 로우를 읽을 때 복사본 블록을 만들어서 쿼리가 시작된 시점으로 되돌려서 읽는다. 변경이 진행 중인 로우를 읽을 때도 Lock이 풀릴때까지 기다리지 않고 복사본을 만들어서 읽는다. 따라서 SELECT 문에 Lock을 사용할 필요가 없다.
- 즉 오라클에서는 DML과 SELECT는 서로 진행을 방해하지 않는다. 물론 SELECT끼리도 서로 방해하지않는다. DML끼리는 서로 방해할 수 있다.
- MVCC 모델을 사용하지 않는 DbMS는 SELECT문에 공유 Lock을 사용한다. 공유 Lock끼리는 호환된다. 두 트랜잭션이 같은 Lock을 설정할 수 있다는 뜻이다. 공유 Lock과 배타적 Lock은 호환되지 않기 떄문에 DML과 SELECT가 서로 진행을 방해할 수 있다. 즉 다른 트랜잭션이 읽고 있는 로우를 변경하려면 다음 레코드로 이동할 때까지 기다려야하고, 다른 트랜잭션이 ㅂ녀경중인 로우를 읽으려면 커밋할때까지 기다려야한다.
- DML 로우 Lock에 의한 성능 저하를 방지하려면 OLTP를 처리하는 주간에 Lock을 필요 이상으로 오래 유지않도록 커밋 시점을 조절해야한다. 그에 앞서 트랜잭션이 빨리 일을 마치도록 관련 SQL을 튜닝해야한다.
- DML 테이블 Lock (TM Lock)
- 로우 Lock을 설정하기전에 테이블 Lock을 먼저 설정한다. 현재 트랜잭션이 갱신중인 테이블 구조를 다른 트랜잭션이 변경하지 못하게 막기 위해서다.
- 로우 Lock은 항상 배타적 모드를 사용하지만 테이블 Lock에는 여러 가지 Lock 모드를 사용한다. 아래 표는 모드간 호환성을 정리한것이다.
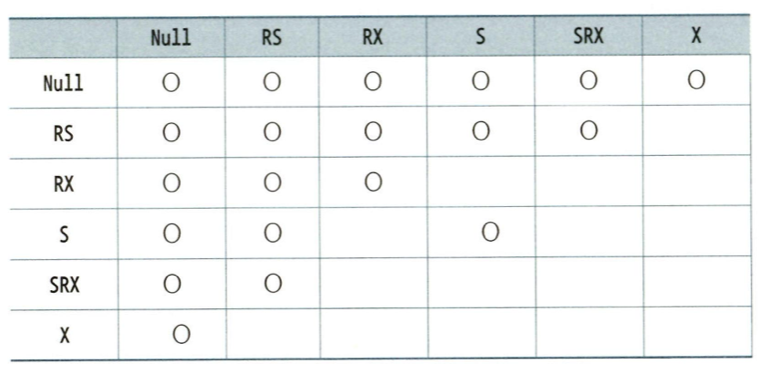
- -
- INSERT, UPDATE, DELETE, MERGE문을 위해 로우 Lock을 설정하려면 해당 테이블에 RX 모드 테이블 Lock을 먼저 설정해야한다.
- SELECT FOR UPDATE문은 10gR1 -> RS, 10gR2이상 -> RX 모드 설정
- RS, RX 간에는 어떤 조합으로도 호환되므로 SELECT FRO UPDATE나 DML문 수행시 테이블 Lock에 의한 경험은 발생하지 않는다. 같은 로우를 갱신하려고 할때만 로우 Lock에 의한 경합이 발생한다.
- 즉 테이블 Lock은 테이블 Lock을 설정한 트랜잭션이 해당 테이블에서 현재 어떤 작업을 수행 중인지 알리는 일종의 푯말이다. 그래서 어떤 모드를 사용했는지에 따라 후행 트랜잭션이 수행할 수 있는 작업의 범위가 결정된다.
COMMIT
- 블로킹 : 선행 트랜잭션이 설정한 Lock 때문에 후행 트랜잭션이 작업을 진행하지 못하고 멈춰있는 상태 -> 해결하려면 커밋
- 교착상태 : 두 트랜잭션이 특정 리소스에 Lock을 설정한 상태에서 맞은편 트랜잭션이 Lock을 설정한 리소스에 또 Lock을 설정하려고 진행하는 상황을 말한다.

이 메시지를 받은 트랜잭션은 커밋 또는 롤백을 결정해야한다. 이것은 예외처리안하면 대기 상태 지속된다.
불필요하게 트랜잭션을 길게 정의하지 않도록 주의해야한다.
- Undo 세그먼트 고갈
- Undo 세그먼트 경합 유발
DML Lcok 때문에 동시성이 저하되지 않도록 적절한 시점에 커밋해야한다.
너무 커밋이 자주 발새앟면
- 서버 프로세스가 LGWR에게 로그 버퍼를 비우도록 요청하고 동기방식으로 기다리는 횟수 증가 -> 성능 느려짐
- 10gW2부터 제공하는 비동기식 커밋과 배치 커밋 활용 방안 검토

'SQLP > SQLP' 카테고리의 다른 글
| 7.1 통계정보와 비용 계산 원리 (0) | 2025.02.25 |
|---|---|
| 6-4. Lock과 트랜잭션 동시성 제어 (2) (0) | 2025.02.23 |
| 6.3 파티션 을 활용한 DML 튜닝 (2) (0) | 2025.02.22 |
| 6.3 파티션을 활용한 DML 튜닝 (1) (0) | 2025.02.22 |
| 6-1, DML 기본 튜닝 (2) (0) | 2025.02.21 |